XGBoost와 관련된 내용은 고려대학교 산업경영공학부 DSBA 연구실 강필성 교수님의 강의를 듣고 작성했다.
이전 파트는 앙상블과 그에 따른 배깅, 부스팅 기법에 대해 알아보았다. 이 부스팅 기법에는 GBM이 있었는데, 이런 GBM의 비효율적인 측면을 개선하고자 나온 LightGBM까지 알아보았다. 하지만, GBM의 개선 버전은 LightGBM 뿐만 아니라 XGboost, Catboost도 존재한다. 이런 개선버전들은 머신러닝 경진대회에서 자주 사용되는 부스팅 기법이기에 더 알아볼 필요가 있다고 생각되어 이번 파트에서 XGboost에 대해 추가적으로 공부를 하고 작성해 보았다.
XGBoost (eXtream Gradient Boosting)
이론

XGBoost는 eXtream Gradient Boosting으로 이름 그대로 Gradient Boosting을 극한까지 끌어왔다! 라는 의미를 가지고 있다. 즉, XGBoost는 GBM과 비슷한 원리로 Boosting이 진행되는데 GBM에서 어떻게 하면 조금더 빠르고 대용량 데이터를 다룰까? 를 목표에서 시작한 기술이다. XGboost는 다른 알고리즘들과는 다르게 일반 알고리즘 부분에 더해서 속도를 향상하기 위해 하드웨어단 까지 내려가 다루는 부분이 있다. (캐시를 사용하여 데이터의 입출력을 빠르게 단축시키는 등, ...) 이런 부분을 자세히 다루기 보다는 간단히 언급하고 알고리즘에 초점을 맞추어 설명하려 한다. 사실 XGBoost는 속도를 향상시키기 위해 GBM이 하는 동작을 근사하여 답을 맞추려고 하기에 GBM보다 성능면에서 항상 좋은 것은 아니다. 하지만, 하나의 모델에서 더 많은 데이터를 사용할 수 있고 기존 Boosting과는 다르게 병렬처리까지 가능하여 많이 쓰이고 있는 머신러닝 기법 중 하나이다.

이제 이 XGBoost가 어떤 방식으로 학습을 진행하고 답을 찾아나가는지 알아보자.
가장 먼저 XGBoost가 더 좋은 속도를 보이기 위해서 사용한 기법은 Split Finding algorithm을 사용할 때 기존 의사결정나무에서 사용된 exact greedy algorithm 즉, 전주 조사(모든 것을 다 확인하여 split point를 찾는 것)를 사용하는 것이 아닌, approximate algorithm을 사용하여 일부만을 조사하고 split point를 찾게하여 속도를 줄였다. 즉, XGBoost는 exact greedy alogrithm의 데이터가 너무 클 시에 시간이 오래 걸리며 아예 동작이 되지 않는 단점과 한번에 모두를 진행하다 보니 분산처리가 불가능하다는 단점을 해결하고자 approximate alogirtm을 사용하게 된 것이다.

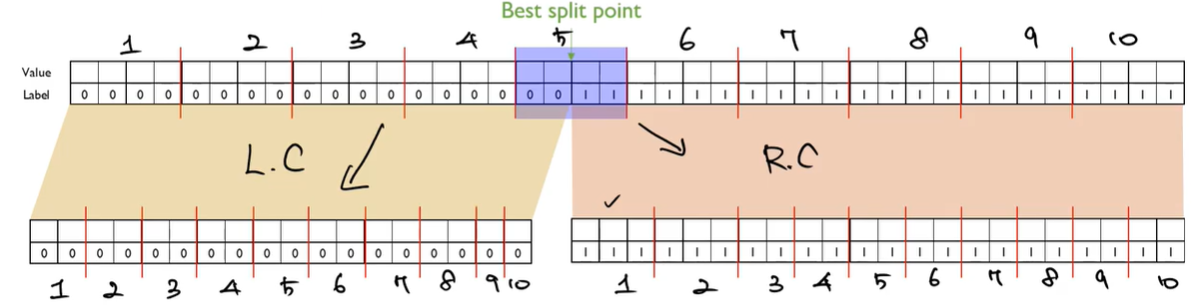
이 알고리즘에서 중요한 부분은 결국 보라색 형광펜을 칠한 부분, 즉 전체 데이터를 정해진 비율에 의해 나누는 부분이다. 이 때 분할은 tree형식으로 혹은 split형식으로 이루어질 수 있다. 이제 이 나누어진 데이터 즉, 각각의 bucket (sk1, sk2, ..)에 대해 따로 따로 split point를 찾아주게 된다. 이를 예시를 통해 확인해 보자.
일단 먼저 기존의 exact greedy algorithm은 빨간선이 아닌 초록색 선과 같이 모든데이터를 살펴보며 모든 split point에 대해 측정을 진행하며 최적의 gradient를 얻는 split point를 결정하게 된다. 결국 이는 데이터가 40개가 있다면 39번의 split을 진행하는 것이다.

그럼 이제 XGBoost의 변경된 alogrithm인 approximate algorithm을 살펴보자. 해당 알고리즘의 데이터는 정렬되어있다고 가정을 하고 시작한다. 그 후 각 데이터를 정해진 비율에 맞게 일부 데이터로 분할한다. (빨간색 선이 분할의 표시) 이제 각 데이터셋에서의 split point를 찾게 되는 것이다. 여기서 1,2,3의 과정에서는 같은 레이블만 존재하기에 유의마한 gradient를 얻지 못할 것이다. 하지만 보라색 표시가 된 bucket에 대해 split point를 찾을 경우 유의미한 gradient를 얻게 되며 기존의 exact greedy algorithm과 유사한 split point를 얻게 될 것이다. (여기선 극단적인 예시, 물론 정확히 똑같은 경우는 드뭄)

이 둘의 차이는 사실 지금부터가 진짜라고 할 수 있다. exact greedy 같은 경우 split point를 찾기 위해 분할을 39회 연속적으로 실시하게 된다. 하지만 approximate 같은 경우 3(각 bucket에서 진행되는 분할 수)x10(bucket의 수)의 30회로 줄게 된다. 여기서 중요한 부분은 XGBoost는 각 bucket에 대해 병렬적으로 처리를 할 수 있다는 것이다. 예를 들어 내가 병렬적으로 1번에 5개의 bucket을 처리할 수 있다면 exact greedy와 약 6~7배의 속도차이를 얻을 수 있는 것이다.
그럼 이제 우린 best split point를 찾았으니 이를 child로 분할할 일이 남았다. 이 개념이 위에서 말한 tree 분할과 split 분할이다. tree 분할은 global varient라고도 불린다. 이는 child로 분할할 때 해당 분할을 그대로 받아오는 것을 말한다. 즉, child의 bucket은 쪼개진 그대로의 개수를 받아온다. (예시에서는 bucket의 수가 반으로 줄어듦)

반면에 split 분할(local varient)은 parent의 bucket개수를 그대로 유지한다.
일반적으로 똑같은 eps(1/eps 로 bucket 생성)이라면 local variable이 더 성능이 좋고 eps을 줄인다면 global varient가 더 성능이 좋게 나온다. (기존의 전수 조사, exact greedy와 거의 유사한 성능이 나올정도로 좋음)

다음은 실제 데이터에서 생길 수 있는 결측치와 sparse 데이터에 대한 처리 부분이다. 사실 이부분은 전처리 부분인데, XGBoost는 이런 부분까지 처리할 수 있도록 설정되어 있다. 이는 2가지 경우에 대한 선택이 진행된다. 먼저 결측치가 있는 데이터에 대해 가장 오른쪽으로 보내버린다. 그 후 split point를 찾고 다음으로는 이 결측치들은 왼쪽으로 보내 split point를 찾는다. 이제 이 둘의 split point의 gradient 효과를 비교한 후 더 적절한 split point를 찾아준다. 이렇게 되면 당연히 왼쪽으로 보내버린 경우가 더 좋은 결과를 얻을 것이다.
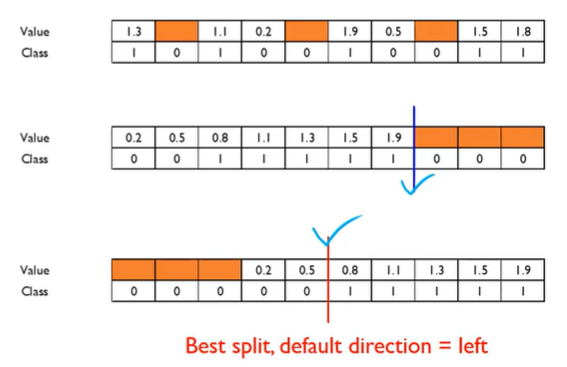
이제 이러한 결과를 바탕으로 결측치 데이터가 들어오게 되면 위에서 정해진 split point를 기준으로 해당 child에게 그냥 보내버린다는 것이다. 예를 들면
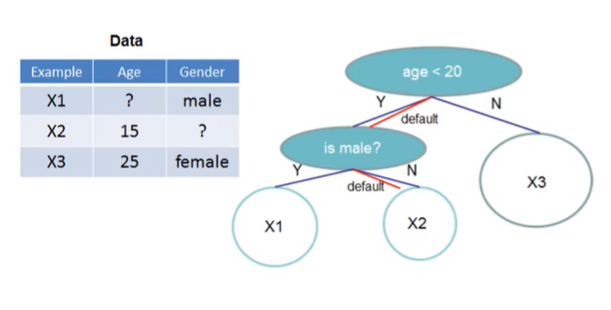
Age가 missing이고 이 age에 대해서 위의 처리를 진행한 결과 split point에 따라 결측치는 왼쪽 child로 보내야된다는 결과가 나왔다고 하면, 이제 어떤 새로운 데이터에 age가 결측치라 하면 무조건 왼쪽 child로 보내버리는 것이다.
이렇게 XGBoost는 전체 데이터를 일부 bucket으로 나누며 병렬적으로 처리하면서 기존의 GBM보다 split point를 보다 효율적이고 빠르게 결정하고 결측치에 대해서도 알고리즘을 통해 보다 적절히 split 되도록 설정해 두었을 뿐만 아니라 GBM에서는 다루지 않았던 하드웨어적인 요소까지 접근하여 속도를 향상시키는데 집중하였다.
실습
실습은 저번 파트에서 진행했던 UniversalBanck 데이터를 사용한다. [참고]
import pandas as pd
import numpy as np
# 데이터 로드
bank_df = pd.read_csv('UniversalBank.csv')
# 필요없는 데이터는 버리고 특성변수와 목표값으로 분리
x = bank_df.drop(['ID','ZIPCode','PersonalLoan'], axis=1)
y = bank_df['PersonalLoan']
print(set(y)) # {0,1}
x.head(3)
이제 XGBoost를 선언하고 바로 최적의 하이퍼파라미터를 찾아 주어 예측 정확도를 확인해보자.
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
xgb = XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=4)
params = {
'n_estimators':[100,200,300],
'learning_rate':[0.2, 0.1, 0.01,],
'max_depth':[4,6,8,10]
}
grid = GridSearchCV(estimator=xgb, param_grid=params, cv=10, scoring='roc_auc', n_jobs=-1)
grid.fit(x, y)
print(grid.best_params_)
print(grid.best_score_)
XGBoost는 기본적으로 CART알고리즘을 사용하는 의사결정나무를 기본 모델로 가지고 시작하여 max_depth가 있는 것을 볼 수 있고 이전에 배웠던 GBM과 같이 n_estimators와 learning_rate를 설정할 수 있다.
결과적으로 0.99의 높은 수준의 정확도를 얻는 하이퍼파라미터를 얻을 수 있는 것을 확인하였다.
여기서 더 나아가 XGBoost가 제공하는 유용한 기능들을 살펴보자.
먼저, XGBoost는 과적합에 취약하므로 자체적으로 EarlyStopping 기능(part 10에서 다루었음)을 제공한다. 즉, 정해진 반복횟수 만큼 계속해서 weak learner를 만들며 학습하던 도중 과적합이 의심되는 순간(검증오차의 변화가 없는 경우) 학습을 종료한다.
# 교차검증이 아닌 학습 도중의 검증이 필요하므로 고정분할법사용
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.2, stratify=y, random_state=11)
from XGBoost impmort XGBClassifier
xgb = XGBClassifier(n_estimators=300, learning_rate=0.1, max_depth=4) # 하이퍼 파라미터는 임의로 설정
xgb.fit(x_train,y_train, early_stopping_rounds= 100, eval_metric='logloss', eval_set=[(x_test,y_test)], verbose=1)
# 학습 시 early_stopping 적용.
print(xgb.score(x_test,y_test)) # 0.988
XGBoost 학습 시(xgb.fit 부분) eraly_stopping_rounds를 100으로 설정해주면 100번 동안 설정해준 eval_set(검증데이터)의 검증 오차(eval_metric, logloss로 측정)가 변화가 없을 경우 위와 같이 학습을 종료해준다. 해당 결과는 198번째 반복에서 학습을 중단한 것이다. 즉, 98번재부터 198까지의 검증 오차의 개선이 없었기에 198번째에서 멈추고 98번째의 모델을 최적의 모델로 설정한 것이다.
다음은 XGBoost가 학습하며 어떤 특성변수가 중요하다고 판단되었는지 확인할 수 있는 기능이다. 이는 xgboost의 plot_importance를 통해 확인할 수 있다.
import matplotlib.pyplot as plt # 시각화를 위한 툴
from xgboost import plot_importance # feature importance 확인
fig,ax = plt.subplots() # 그래프 설정
plot_importance(xgb, ax=ax) # feature importance 시각화
해당 그래프를 보아하니 Income과 CCAvg라는 특성을 굉장히 중요하게 생각했다는 것을 알 수 있다. 즉, 이 두 변수가 분류에 있어서 가장 많은 영향을 주었다는 것이다. 이렇게 XGBoost는 자체적으로 어떤 특성변수를 더 중요하게 생각하며 분류를 진행했는지 확인할 수 있게 해준다.