2021년도에 대학교 과목으로 들었던 '기계학습' 강의를 복습 및 정리 + 추가적인 공부를 위해 이 글을 작성한다. (세종대학교 최유경 교수님 '2021 기계학습'수업)
What is ML?
먼저 Machine Learning 즉, 기계학습이란 무엇일까?
사전적 정의로는 '경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구로 인공지능의 한 분야'이다. 즉, 컴퓨터가 알아서 데이터의 패턴 및 분포를 파악하며 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야라고 할 수 있다.
이런 기계학습은 대표적으로 지도학습, 비지도학습, 강화학습 3가지로 분류할 수 있다.

1. 지도학습(Supervised Learning)
지도학습은 말 그대로 학습을 지도하는 가이드 라인(결과값)이 있다고 생각하면 된다. 즉, 입력과 결과값(목표값)을 이용하여 학습을 진행한다. 이는 크게 분류(classification)와 회귀(regression)로 나누어진다. 대표적인 학습 모델로는 SVM(support vector machine), Decision Tree, KNN, Linear/Logistic regression 등이 있다.
2. 비지도학습(Unsupervised Learning)
비지도학습은 말 그대로 학습을 지도하는 가이드 라인(결과값)이 없다고 생각하면 된다. 즉, 입력값에 대한 결과값(목표값)이 주어지지 않은 상태에서 데이터가 어떻게 구성되었는지를 중점적으로 학습을 진행한다. 이는 크게 군집화(clustering), 변환(transform), 연관(association)으로 나누어진다. 대표적인 학습 모델로는 K-means 클러스터링이 있다.
3. 강화학습(Reinforcement Learning)
강화학습은 가이드 라인(결과값)이 주어져 있지 않은 상태에서 리워드를 통해 학습을 진행한다. 즉, 강화학습은 어떤 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하며 학습이 진행된다. 대표적인 학습 모델로는 MDP(Markov Decision Process)가 있다.
이런 기계학습의 요소 요소를 깊이 보기 전 우리는 이 기계학습이 어떻게 탄생하고 활성화가 되었는지와 관련된 데이터에 대해서 알아볼 필요가 있다. (기계학습에 있어서 데이터는 굉장히 중요함, 과장하면 거의 전부라고 볼 수 있음)
데이터 이해
그냥 일반적인 데이터는 사실 기존에도 있었다고 할 수 있다. 하지만 지금은 일반적인 데이터가 아닌 빅데이터의 시대가 왔다. 빠른 통신, 충분한 클라우드, 데이터가 발생하지 않던 곳에서 데이터가 발생하게 하는 IoT 등의 기술의 하모니를 통해 빅데이터가 출현했다. 그러면서 자연스럽게 이렇게 거대해진 데이터에서 숨은 패턴을 찾아내려 하는 데이터 분석, 인간의 지능을 묘사하여 데이터 분석의 능력과 수준을 끌어 올리는 인공지능 및 머신러닝이 활성화되기 시작한 것이다.
결국 이렇게 됨에 따라 데이터 분석을 통한 가치의 재생산이 발생하는 것과 같은 패러다임의 변화가 시작되었다.

그렇다면 이런 빅데이터들을 어떻게 분석해야 될까? 말 그대로 빅 데이터인데, 분석가들이 전부 일일히 감당해야 할까?이런 문제때문에 Machine Learning이라는 것이 발생한 것이다. 분석가와 같은 똑똑한 기계를 만들어 "생각의 아웃소싱"을 실현하자는 것이 목표였다. 결국 패러다임의 변화와 동시에 기계를 바라보는 측면이 물건 생산을 위해 육체노동을 기계로 자동화하자는 산업혁명에서 정보 추출을 위해 정신노동을 기계로 자동화하자는 머신러닝으로 바뀌게 된 것이다.
그렇다면 이런 데이터들을 그냥 바로 기계학습을 이용하여 새로운 가치를 창출하면 되는 것일까? 아니다.
데이터를 통해 새로운 가치를 창출하기 위해 우린 크게 두가지를 해야된다고 볼 수 있다. 바로 '데이터 시각화'와 '데이터 전처리'이다.
데이터 시각화
사실 데이터 시각화는 기계학습에 데이터를 학습시키기 위한 필수적인 조건은 아니다. 하지만 기계학습에 학습에만 사용되는 데이터로 보는 것보다 더 나아가 최종 목표인 새로운 가치를 창출하기 위해서 시각화는 필수이다.
먼저 '데이터 시각화'란 광범위하게 분산된 방대한 양의 자료를 분석해 한눈에 볼 수 있도록 도표나 차트등으로 정리하여 제공하는 것을 말한다. 이런 데이터 시각화를 제공하게 되면 즉각적인 상황 판단이 가능해지며 정보의 빠른 확산을 촉진하게 된다. 결국 이를 통해 명확하고 효과적으로 정보를 커뮤니케이션할 수 있게 된다.
이때 우린 '데이터'와 '정보'라는 두가지 의미를 구분할 필요가 있다. '데이터'는 말 그대로 발견, 수집의 결과인 일정의 기초자료로서 정보를 만들기 위한 원자재와 같은 것이라고 할 수 있다. 여기서 중요한 점은 데이터는 정보 자체는 아니라는 것이다. 즉, 정보로서의 가치가 부족하여 분석이 필요한 대상이라고 볼 수 있다. 그에 반해 '정보'는 '데이터'와 달리 그 자체만으로 의미가 있다. 즉, 데이터가 내포하는 의미를 전달한다고 보면 된다. 결론적으로 데이터가 정보로서 가치를 갖기 위해서는 조직화 및 변형이 필요하며 의미를 전달하기 위한 형태로 표현되어야 한다. 이 때 필요한 것이 바로 '데이터 시각화'이다. [데이터 → 시각화 → 정보]
이런 데이터 시각화를 위한 도구들은 다양하다.
1. 엑셀
엑셀은 누구나 쉽게 그래프를 만들 수 있지만 심도 있는 분석이난 그래픽이 필요할 땐 사용하지 않는다.
2. 구글 차트
구글 차트는 속도가 빠르며 초보자를 위한 기본 API가 제공되어 접근성이 좋다. 실제로도 데이터 분석가들이 자주 사용하는 도구라고 할 수 있다.

3. D3.js
D3.js 는 데이터 시각화 프레임워크를 목적으로 자바스크립트로 개발되었다. 기본적으로 HTML, SVG, CSS를 이용하여 웹상으로 사용자에게 데이터 시각화 정보를 제공하기 위해 사용된다.

4. 파이썬 [중요!]
파이썬이 아마 개발자들이 사용하는 대표적인 시각화 툴이라고 볼 수 있다. 대규모 데이터를 무리없이 다룰 수 있어 큰 규모의 계산에 쓰이고 기존의 제공하는 라이브러리들이 많기에 적은 코드만으로 많은 기능을 만들 수 있다. 미학적으로는 구글 차트나 D3.js보다 부족하지만 데이터 탐색 단계에서 활용하기에 부족함이 없다. 또한 파이썬은 앞서 말한 것처럼 데이터 시각화 뿐만 아닌 인공지능 모델 설계 등 end to end로 ML을 이용하기에 적합하여 많이 쓰이고 있다.

데이터 전처리
지금까지는 데이터를 정보로 만드는 데에 집중한 '데이터 시각화'에 대해서 알아보았고, 이 정보를 직접 기계학습에 이용하기 위해선 이제 '데이터 전처리'가 필수이다. 데이터 전처리를 알아보기 전 먼저 데이터 분석에 사용되는 파이썬 라이브러리 'Pandas' 및 'Scikit-learn'을 알아야 한다. (앞으로 이 라이브러리를 사용해서 실습을 진행)
'Pandas'란, 파이썬에서 사용하는 데이터분석 라이브러리로, 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 되며 보다 안정적으로 대용량의 데이터들을 처리하는데 매우 편리한 도구이다. 자료 탐색과 정리에 아주 유용하여 데이터 분석에 빠질 수 없는 필수 패키지다. 원래는 R 언어에서 제공하는 데이터프레임 자료형을 파이썬에서 제공할 목적이었으나 더 다양한 기능이 추가되었다.
'Scikit-learn'은 머신러닝 교육을 위한 최고의 파이썬 패키지다. scikit-learn 패키지의 장점은 다양한 머신러닝 학습 모델을 하나의 패키지에서 모두 제공하고 있다는 점이다. 또한, 머신러닝 모델 뿐만 아닌 다양한 데이터 전처리 도구를 제공한다.
그럼 이제 본격적으로 데이터 전처리에 대해 알아보자. '데이터 전처리'란, 데이터의 품질을 올리며 기계학습에서의 학습 시 올바른 학습을 유도하기 위해 진행해 주는 과정이다. 이런 전처리에는 데이터 실수화, 데이터 변환, 데이터 정제, 데이터 통합 및 축소 등 다양한 주요기법이 존재한다. 이 기법들은 데이터에 따라 일부만 진행하기도 하고 전부 진행해하기도 한다.
1. 데이터 실수화 (Data Vectorization)
데이터 실수화는 범주형 자료, 텍스트 자료, 이미지 자료 등을 컴퓨터가 인식할 수 있는 실수로 구성된 형태로 전환하는 것을 말한다. (컴퓨터가 인식하지 못하는 데이터는 사실상 의미가 없는 데이터가 됨) 각각의 자료형에 따른 전처리 방법은 다르다.
1) 범주형 자료의 실수화
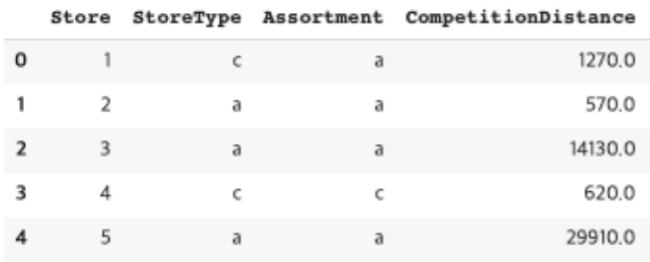
범주형 자료는 객관식에서의 보기라고 보면 된다. 예를 들어 'Seoul', 'Dubai', 'LA' 등 정해진 범주 안의 자료라고 생각하면 된다. 하지만 컴퓨터는 이런 텍스트,범주형 자료는 인식할 수가 없다. 따라서 이들을 수치로 변환해주는 과정이 필요하다. 이것이 바로 실수화이다.

범주형 자료는 보통 One-Hot Encoding을 통해 실수화를 진행한다. 이는 pandas의 get_dummies함수 혹은 Scikit-learn의 DictVectorizer함수를 통해 변환할 수 있다.
import pandas as pd
city = pd.DataFrame({'city':['Seoul', 'Dubai', 'LA'], 'temp':[20.1, 32.4,23.6]})
city
pd.get_dummies(city['city'])
city = [{'city':'Seoul','temp':20.1},{'city':'Dubai','temp':32.4},{'city':'LA','temp':23.6}]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False) #COO 표현식
new = vec.fit_transform(city)
pd.DataFrame(new, columns=vec.get_feature_names())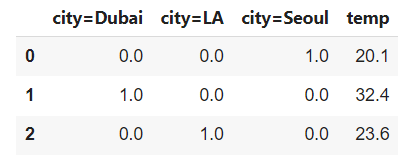
하지만 여기서 중요한 점은 위의 예시에서 볼 수 있듯이 행렬의 대부분이 0 값을 가진다. 즉, 메모리 낭비가 심해지게 되어 연산시 시간이 많이 소모되는 단점이 있다. 'Scikit-learn'에서는 이를 CSR 표현식(Compressedd Sparse Row, 가로의 순서대로 재정렬하는 방법으로 행에 관여하여 정리 압축한 것, 메모리가 적게 들고 빠른 연산 가능)을 통해 해결할 수 있다.
city = [{'city':'Seoul','temp':20.1},{'city':'Dubai','temp':32.4},{'city':'LA','temp':23.6}]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=True) # CSR 표현식 -> 출력을 통해 확인할 수 없어짐
vec.fit_transform(city) # toarray()를 통해 CSR의 압축을 풀고 결과를 확인할 수는 있음
2) 텍스트 자료의 실수화
범주형 자료와 마찬가지로 텍스트 자료는 컴퓨터가 인식을 하지 못한다. 그러므로 이들 또한 실수화가 필요하다. 이는 자연어처리 분야에서 필수적이며 높은 중요도를 가지고 있는 부분이라고 할 수 있다. Word Embedding이라고 부르기도 한다. Word Embedding에는 더 나은 자연어처리를 위한 굉장히 다양한 방법들이 존재한다. 여기선 기본적인 word embedding 방법인 CountVectorizer, TF-IDF에 대해서 설명한다.
먼저 CountVectorizer는 단어 출현 횟수를 이용하여 데이터를 실수화 한다.

예시와 같이 한문장에서의 출연빈도를 통해 해당 단어를 표현한다.
text = [ '떴다 떴다 비행기 날아라 날아라',
'높이 높이 날아라 우리 비행기',
'내가 만든 비행기 날아라 날아라',
'멀리 멀리 날아라 우리 비행기']
from sklearn.feature_extraction.text import CountVectorizer
vec2 = CountVectorizer() #sparse=True, CSR표현식
pd.DataFrame(vec2.fit_transform(text).toarray(), columns=vec2.get_feature_names())
하지만 출현 횟수가 정보의 양과 비례하는 것은 아니므로 CountVectorizer 보다는 TF-IDF(Term Frequency Inverse Document Frequecny)를 더 사용하는 추세이다. 이는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 측정하여 자주 등장하여 분석에 의미를 갖지 못하는 단어(조사, 관사 등)의 중요도를 낮추는 기법이다. 즉, 문서에서는 많이 나오지는 않지만 해당 문장에서 많이 나오면 큰 가중치를 줘 중요도를 높인다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfid = TfidfVectorizer() #sparse=True, CSR
pd.DataFrame(tfid.fit_transform(text).toarray(), columns=tfid.get_feature_names())
이외에도 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론의 Word2vec, 카운트 기반과 예측 기반을 모두 사용하는 방법론인 Glove, 하나의 단어 안에도 여러 단어들이 존재하는 것으로 간주하여 word2vec과 같이 임베딩을 진행하는 FastText, 사전 훈련된 언어 모델을 사용하는 ELMo 등 정말 다양하고 좋은 성능을 가진 텍스트 자료의 실수화(word embedding)가 있다.
2. 데이터 변환 (Data Transformation)
그냥 제목만 봐서는 데이터 변환이 왜 필요한지 감이 오지 않을 것이다. 하지만 데이터 변환 또한 전처리에 있어서 굉장히 중요하게 취급되고 있다. 그렇다면 왜 변환이 필요할까? 머신러닝은 데이터가 가진 특성들을 비교하여 데이터의 패턴을 찾는다. 하지만 데이터가 가진 특성 간 스케일 차이가 심하면 패턴을 찾는데 문제가 발생한다. 그래서 데이터들의 분포를 표준화 혹은 정규화가 필요하다.


하지만 보통 표준화보다는 정규화를 많이 사용한다. 단, 데이터 특성이 Bell Shape(평균에 몰려있는 상태, 평균에서 양쪽으로 대칭) 이거나 이상치가 존재할 경우 표준화가 더 유용하다고 한다.
# 표준화
from sklearn.preprocessing import StandardScaler
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
scaler = StandardScaler()
print(scaler.fit_transform(data))
"""
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
"""
print(scaler.transform([[2, 2]])) # [[3. 3.]] / 현재의 scaler에 맞게 데이터 변환# 정규화
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler()
print(scaler.fit_transform(data))
"""
[[0. 0. ]
[0.25 0.25]
[0.5 0.5 ]
[1. 1. ]]
"""
print(scaler.transform([[2, 2]])) # [[1.5 0. ]] / 현재의 scaler에 맞게 변환# 최근 각광받고 있는 RobustScaler(표준 정규화)
: 평균과 분산대신, 중간값과 사분위 값을 조정하며 이상치 데이터를 제거하여 고려함. 즉, 견고한 scaler
from sklearn.preprocessing import RobustScaler
data = [[ 1., -2., 2.],
[ -2., 1., 3.],
[ 4., 1., -2.]]
scaler = RobustScaler()
print(scaler.fit_transform(data))
"""
[[ 0. -2. 0. ]
[-1. 0. 0.4]
[ 1. 0. -1.6]]
"""
3. 데이터 정제 (Data Cleaning)
데이터 정제란, 없는 데이터는 채우고, 잡음 데이터는 제거하고 모순 데이터를 올바른 데이터로 교정하는 것을 말한다.
학습에 있어서 데이터 정제 또한 필수다. 기계는 정해진 특성(데이터 속 특징)에 대해서 학습을 진행하는데 이때 중간 중간 비어 있는 특성, 혹은 잘못된 특성이 존재하다면 학습은 제대로 이루어질 수 없기 때문이다. 사실 이 데이터의 부재, 잡음 등은 데이터를 얻자 마자 확인할 수 있는 부분이 아니다. 이때 필요한게 바로 데이터 시각화이다. 그래프나 차트를 통해서 데이터들을 시각적으로 표현하면 비어 있는 데이터나 이상치를 어렵지 않게 발견해 낼 수 있다. 그럼 발견 후 이런 잘못된 데이터들은 어떻게 처리해주어야 할까? 간단히 말하자면 그 데이터를 채워주거나 버리면 된다. 하지만 안그래도 학습할 수 있는 데이터가 충분치 않은 상황에서 버리는 것은 비효율적이기에 보통 데이터를 채워주는 방식을 택한다. 이때 사용되는 것이 sklearn의 SimpleImputer() 함수이다. (물론 직접 통계적으로 분석 후 채울 수도 있음.) SimpleImputer()는 결측치나 이상치(이상치는 버린 후 결측치로 만들어줘야 함)를 평균, 중위수, 최빈수로 대처하는 기법을 제공한다. 즉, 비어 있거나 이상한 데이터를 다른 데이터들의 특성으로서 채워주는 것이다.
import numpy as np
data_m = np.array([[1,2,3,None],[5,np.NAN, 7,8], [None,10,11,12],[13,np.nan,15,16]])
pd.DataFrame(data_m)
from sklearn.impute import SimpleImputer
imp_mean= SimpleImputer(strategy='mean') # or median, most_frequent, constant 가능.
# 이때 constant는 내가 지정한 값으로 모든 결측치를 채우는 것
pd.DataFrame(imp_mean.fit_transform(data_m))
4. 데이터 통합 및 축소 (Data Integration, Data Reduction)
데이터 통합은 여러 개의 데이터 파일을 하나로 합치는 과정이다. 이는 보통 데이터 수집 과정에서 데이터의 feature를 합치거나 데이터의 instance들을 합치기 위해 사용된다. 데이터 축소는 데이터가 과도하게 큰 경우, 원활한 학습을 위해 데이터의 수를 줄이거나(Sampling), 데이터 차원을 축소(PCA)하는 작업을 말한다.
1) 데이터 통합
보통 Pandas의 merge() 혹은 concat()함수를 사용한다.
# merge : 똑같은 instance에 대한 추가적인 특성을 이을 때 사용
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value1': [1, 2, 3, 5],'value2':[4,4,6,2]})
df2 = pd.DataFrame({'key': ['A', 'C', 'D', 'B'], 'value3': [5, 6, 7, 8]})
pd.merge(df1,df2,on='key')
# concat : 추가적인 데이터를 이어붙이는 것
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value1': [1, 2, 3, 5],'value2':[4,4,6,2]})
df2 = pd.DataFrame({'key': ['E', 'F', 'G', 'H'], 'value1': [5, 6, 7, 8],'value2':[4,6,9,1]})
pd.concat([df1, df2], ignore_index=True)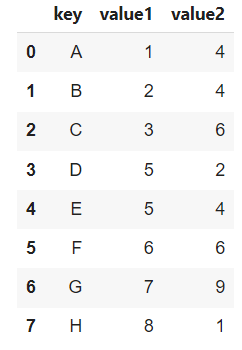
2) 데이터 축소
거대한 데이터 중 원하는 개수로 임의로 선택하는 pandas의 DataFrame.sample()이 있고,
거대한 특징(차원)중 원하는 차원으로 줄이는 sklearn의 decomposition.PCA()가 있다. (추후 자세히 다룰 예정)
df = pd.DataFrame({'num_legs': [2, 4, 8, 0],
'num_wings': [2, 0, 0, 0],
'num_specimen_seen': [10, 2, 1, 8]},
index=['falcon', 'dog', 'spider', 'fish'])
df.sample(frac=0.5) #frac=0.5 : 전체 데이터 개수의 50%를 뽑음/n=2 를 통해 직접 개수 설정 가능
#random_state=1 : 랜덤 시드 고정 -> 추후에 똑같은 결과를 확인할 수 있도록 설정 가능
5. 데이터 균형 (Data Balancing)
특정 클래스의 관측치가 다른 클래스에 비해 매우 낮을 경우 편향된 학습을 방지하기 위해 클래스 비율을 맞추는 작업을 데이터 균형 작업이라고 부른다. 데이터 불균형은 실제로도 날 것의 데이터를 학습에 이용하고자 할 때 자주 경험할 수 있는 상황이다. 나도 실제로 리뷰 긍부정 분류에 있어서 부정리뷰가 긍정리뷰의 10프로도 안되는 불균형을 겪기도 했었다. 이를 해결하기 위해 부족한 클래스를 증가시키는 과대표집(oversampling)방법을 사용하기도 하지만 이는 사실상 적용할 수 있는 도메인이 적어 아직도 많은 연구가 진행되고 있는 분야이기도 하다. 따라서 보통 개수가 적은 클래스에 비율을 맞추는 과소표집(undersampling)을 진행한다.
과대표집(oversampling)에는 대표적으로 개수가 적은 클래스의 데이터를 최근접 이웃(KNN 알고리즘) 알고리즘을 활용하여 새롭게 생성하는 방법인 SMOTE (Synthetic minority oversampling technique), SMOTE의 단점을 보완하고자 주위 데이터의 분포에 따라 발생시킬 합성 데이터의 수를 좀 더 체계적으로 조절하는 방법인 ADASYN(adaptive synthetic sampling method) 등이 사용된다.
from collections import Counter #classifiaction모델 shape 확인
from sklearn.datasets import make_classification #classification모델 생성
from imblearn.over_sampling import SMOTE, ADASYN #과대표집
#불균형 모델 만들기
X, y = make_classification(n_classes=3, weights=[0.03, 0.07,0.9],n_features=2, n_informative=2,
n_redundant=0,n_clusters_per_class=1, n_samples=200, random_state=10)
print('Original',Counter(y))
#Original Counter({2: 180, 1: 14, 0: 6})#과대표집 SMOTE로 자동으로 가장 큰 개수의 클래스의 개수로 균형을 맞춰줌
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
print('Resampled dataset shape %s' % Counter(y_res))
# Resampled dataset shape Counter({2: 180, 1: 180, 0: 180})#과대표집 ADASYN로 가장 큰 개수의 클래스의 개수로 균형을 맞춰줌
ada=ADASYN(random_state=0)
X_syn,y_syn=ada.fit_resample(X,y)
print('Resampled dataset shape from ADASYN %s' % Counter(y_syn))
# Resampled dataset shape from ADASYN Counter({2: 180, 1: 179, 0: 178})


과소표집(undersampling)은 데이터 축소와 같이 해당 소수 클래스의 비율에 맞춰 sampling을 진행하면 된다. (라이브러리 사용도 가능)
pos = pd.read_csv('review_positive.csv')
neg = pd.read_csv('review_negative.csv')
print(len(pos),len(neg)) # 5000, 500
pos.sample(freq=len(neg)/len(pos)) # or n=len(neg)
이렇게 오늘은 기계학습이 뭔지, 기계학습에서 빼놓을 수 없는 데이터는 무엇인지, 데이터는 어떻게 다루어야 하는지 알아보았다.
'공부 > 기계학습 및 인공지능' 카테고리의 다른 글
| Machine Learning (기계학습) - part 3 [로지스틱 회귀(Logistic Regression)] (0) | 2022.01.06 |
|---|---|
| Machine Learning (기계학습) - part 2 [지도학습, KNN(K-Nearest Neighbor)] (0) | 2022.01.06 |
| U-Net 간단 리뷰 (0) | 2021.09.14 |
| SegNet 간단 리뷰 (0) | 2021.09.13 |
| FCN 간단 리뷰 (0) | 2021.09.09 |